早上好,接著是一系列最頭痛的部分了⋯⋯
昨天已經大致了解了他們各自的工作,接著來介紹一下他們的族譜及關係。經過採樣及量化的語音訊號是以時域採樣點的形式存在,而在語音的處理上,我們除了分析它們之外,還會需要利用它們頻域的性質,因此需要將其轉變至其頻域,而處理完語音任務後(如降噪等),還需要變換回時域,來進行播放或者其他操作。下圖是他們之間的族譜大致關係: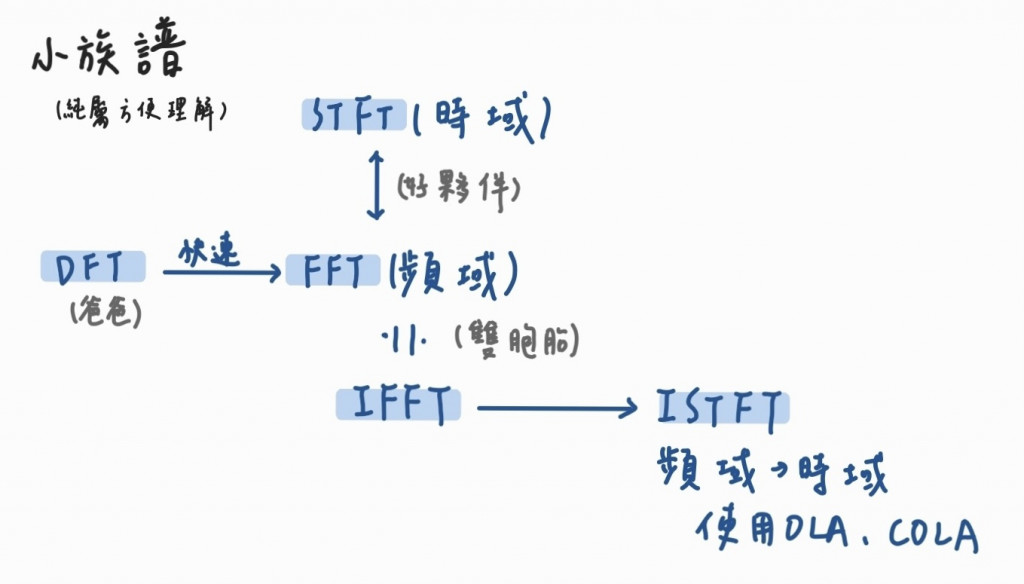
語音訊號最常使用的就是FFT,他是DFT的一種快速實現形式,對於一個離散訊號x(n),其轉換公式如下:
其中的X(k)是訊號的複頻譜,其反應訊號在第k個頻率點上的幅度及相位。
FFT的變換是IFFT,其公式如下:
對語音訊號而言,x(n)均為實數,所以X(k)是關於N/2對稱的,即X(k)=X*(N-k)。
因此,在超過N/2是沒有資訊量的,這可以從理論上來解釋奈奎斯特採樣定理。
今天先告一個段落,明天繼續講奈奎斯特採樣定理。
參考書籍:Hey Siri及Ok Google原理:AI語音辨識專案真應用開發
參考網站:今日無
學習對象:ChatGPT


 iThome鐵人賽
iThome鐵人賽